
How to manage data growth: 4 ways to save your storage
We’re storing more and more data every day, with no signs of slowing down

It’s no secret that we’re storing more and more data every day, with no signs of slowing down. In a recent white paper, Cisco provided storage trends back to 2016 and forecasts to 2021, estimating the growth rate in data for 2019 at about 250 exabytes.
As we store more data, we expect it to be safe and able to survive failure. Our patience with response time has also worn thin: Users expect data to upload quickly and download when requested.
Traditional data center design
Within data centers, the price of storage has dropped. Higher speed SSD storage is very affordable and provides a much higher mean time between failure when compared to legacy spinning drives such as SAS and SATA. While utilizing SSD for primary tier 1 storage has become more affordable, and certainly provides much lower latency, it is still a cost that must be funded.
As organizations expand local storage infrastructure to keep up with the growing capacity and demand for lower latency, every GB of primary storage space should be available for applications and users. We don’t want to tie up our premium storage with replicas of data, stored snapshots, backup data, or test data.
The traditional method for overcoming this dilemma would be to deploy a lower cost tier 2 storage infrastructure configured with lower cost spinning drives – also known as cheap and deep storage.
While this does save capital and expense dollars by deploying a lower cost solution, the storage infrastructure must still be maintained; it will fail and must be available. One conversation a system administrator never wants to have is “I lost your backup” when the DBA or application owner calls for a recovery due to corruption or legal reasons.
Fortunately, there are other approaches to preserving as much of your tier 1 storage as possible.
Traditional method with a cloud twist
A newer method is similar to the traditional method mentioned above. The difference is that the tier 2 storage infrastructure is the cloud. Some companies, however, are hesitant.
They’re not yet comfortable backing up their data in the cloud. They don’t have a firm grasp on the technology. They haven’t established the initial cloud relationship. They’re worried about the response time, and how they’re going to keep costs down while maintaining protection and security. All of these concerns are valid.
Doing a proof of concept will help alleviate some of these concerns. Setting up a backup policy, and then recovering, can reassure anyone unsure of the cloud.
You’ll find that using AWS S3 or Azure BLOB as the target for your backups, snapshots, or replicas is reliable, low cost, maintenance free, and you’ll only pay for what you use. AWS S3, for example, has 11 9s – a clear sign of its durability.
Integration with existing platforms
Many tier 1 storage providers are also integrating cloud storage tiering directly into their products. This is known as native integration.
With native integration, when you buy storage in a native product suite, you get a feature that allows you to offload your protected data to a cloud service.
For example, NetApp introduced FabricPool and tiering capabilities, which allow users to define policies and send snapshots directly to S3, or tier cold blocks of data after a defined amount of time. Another example is Pure Storage, which introduced Portable Snapshots into Purity. This sends snapshots directly to the cloud.
When you use native integration, there’s less infrastructure to manage. You don’t have to purchase or maintain additional software. You don’t require additional servers to support the software. Everything you need comes in the operating system from the storage provider itself.
Using a third-party product
Suppliers such as Veeam and Cohesity are providing software solutions that can be deployed on commodity hardware or virtual appliances. This allows applications to write backups locally and tier older backups to cloud storage.
With this solution, you need to stand up some sort of additional compute infrastructure to support the third-party product as well as integrate it with the cloud storage platform you already have on-site.
Therefore, unlike native integration, you’ll likely need to buy additional servers and products.
Utilizing native services
AWS and Azure both provide gateway appliances, both physical and virtual, allowing users to write locally and tier data to cloud storage services. Both AWS and Azure offer solutions on bare metal or as virtual appliances. Users can utilize industry-standard protocols such as NFS, SMB, or VTL to write backups to the on-premises gateway. The gateway will manage tiering the data to the cloud transparently.
The diagram below shows that the backup, snapshot, and inactive data has been tiered to the cloud, freeing up capacity on the local array.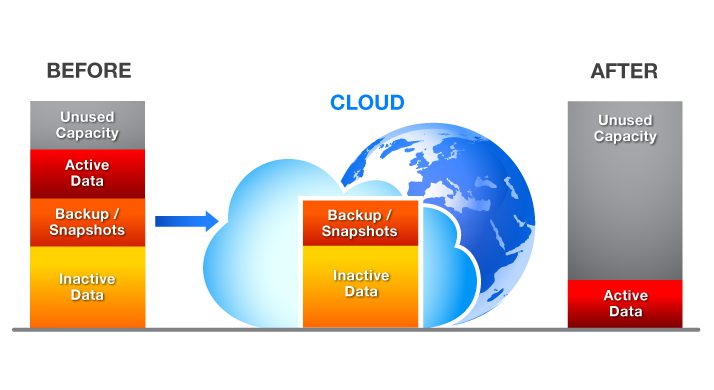 Putting it all together
Putting it all together
The amount of storage we are consuming continues to grow. While storage in the data center is coming down in price, there are new methods of protecting your data and reducing the infrastructure in your data center, while still providing a layer of protection for applications owners.
Enabling functionality with the least disruption possible should be your ultimate goal. You want to save on-premises storage without having to restructure your data center. Whether you choose a solution native to the storage array, a third-party integrated solution, or cloud provider technology, you will free up capacity on locally installed storage arrays.
To learn more about integrating cloud storage for data protection, contact your SHI account executive.
-
 Data center foundations: A comprehensive guide on how to choose the right rack cabinet
Data center foundations: A comprehensive guide on how to choose the right rack cabinet
When choosing rack enclosures and accessories, asking the right questions can have a major impact on your data center's efficiency and hardware lifespan.Reading Time: 5 minutes Discover the key components to consider when choosing a rack enclosure for your data center.
Read More -
 3 ways to extract more value from storage workloads
3 ways to extract more value from storage workloads
Discover our high-level takeaways to optimize your data workloadsReading Time: 3 minutes Your data is one of your most valuable assets. But, a lot of organizations weren’t treating it that way.
Read More -
 Azure Stack HCI: How to enhance efficiency and security with one solution
Azure Stack HCI: How to enhance efficiency and security with one solution
Close the book on obsolete cloud operation.Reading Time: 6 minutes Discover how you can optimize your cloud operations with upgraded Azure Stack HCI—available through SHI.
Read More